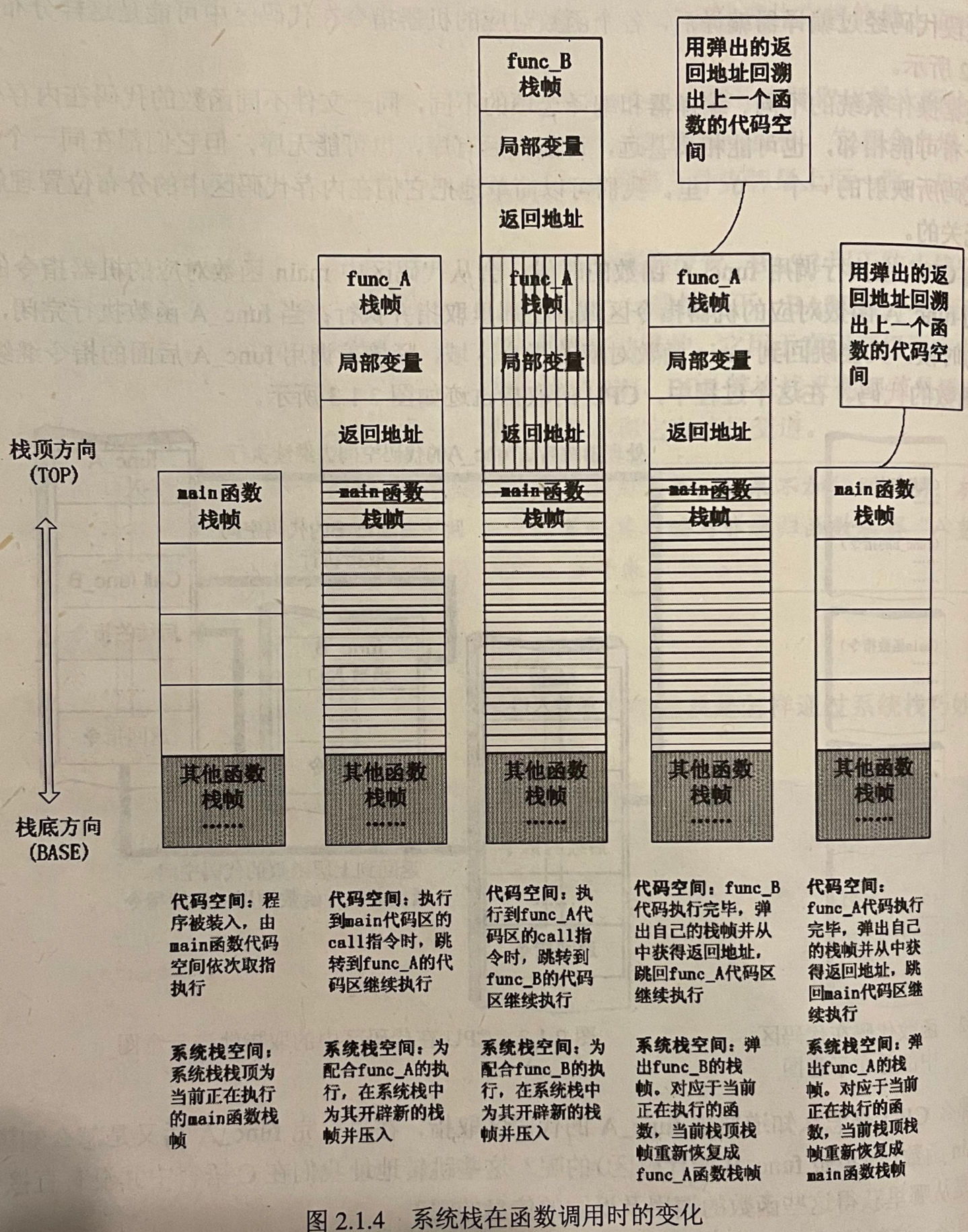
基础知识 漏洞概述 bug与漏洞 bug:影响软件的正常功能,例如,执行结果错误,图标显示错误 。 漏洞:通常情况下不影响软件的正常功能,但被攻击者利用后,有可能引起软件去执行额外的恶意代码。 漏洞挖掘 漏洞分析 漏洞利用 漏洞挖掘 安全性的漏洞往往很难被QA工程师的功能性测试发现。从技术的角度讲,漏洞挖掘实际上是一种高级的测试。学术界一直热衷于静态分析的方法寻找源代码中的漏洞;而在工程界,普遍采用的漏洞挖掘方法是Fuzz。 漏洞分析 当fuzz捕捉到软件中一个严重的异常的时候,当你想要透过厂商公布的简单描述了解漏…
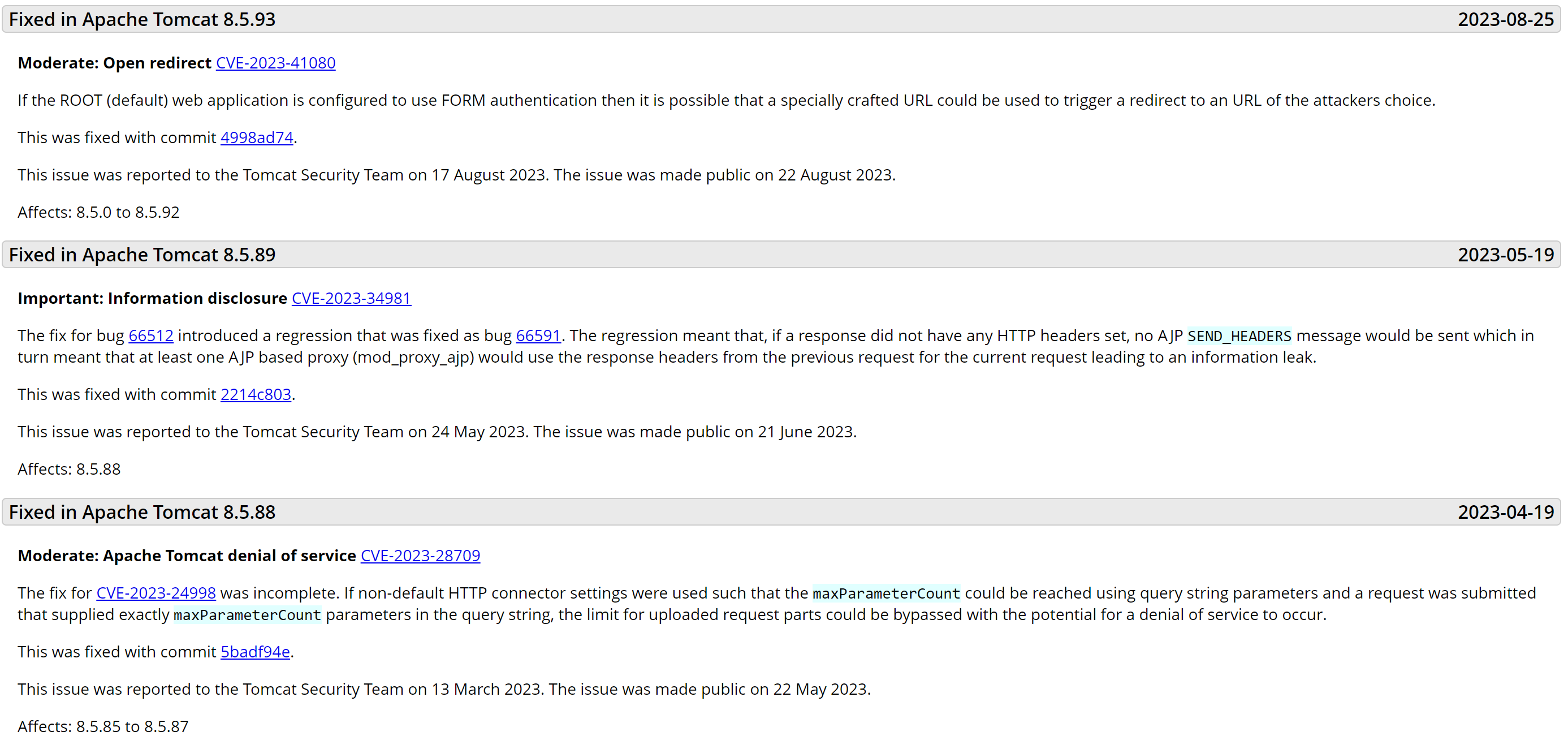
0x00 前言 本文主要记载WEB组件漏洞分析方法,包括漏洞信息搜集,补丁分析,PoC编写,修复方案等内容。以总结无PoC,Exp的Nday漏洞的验证手段。 0x01 信息搜集 漏洞信息的搜集有四种组件官方网站,Github,NVD等漏洞数据库,公众号或技术博客等第三方平台。 1.1 官方网站 一般情况下,被广泛使用的组件会有官方网站,其网站上会对历史漏洞进行记录,记录会包含漏洞编号,漏洞影响版本以及修复的commit。 1.2 Github 开源组件在Github上可以下载历史版本,并且可以看到commit的具体…

0x00 前言 为了解决使用AFL++进行Fuzzing的部分问题,个人决定对AFL的代码进行阅读,此为第一部分。 0x01 变量 1.1 变量相关 1.1.1 计数 rand_cnt 记录种子使用的次数。减到0换个种子。 queued_paths 队列中测试用例的数目 pending_not_fuzzed 进入队列但是没有执行的数目 cycles_wo_finds 没有新路径的循环次数。 queued_at_start 初始的输入数目 link_or_copy 将第一个参数硬连接到第二个参数。 nuke_resu…
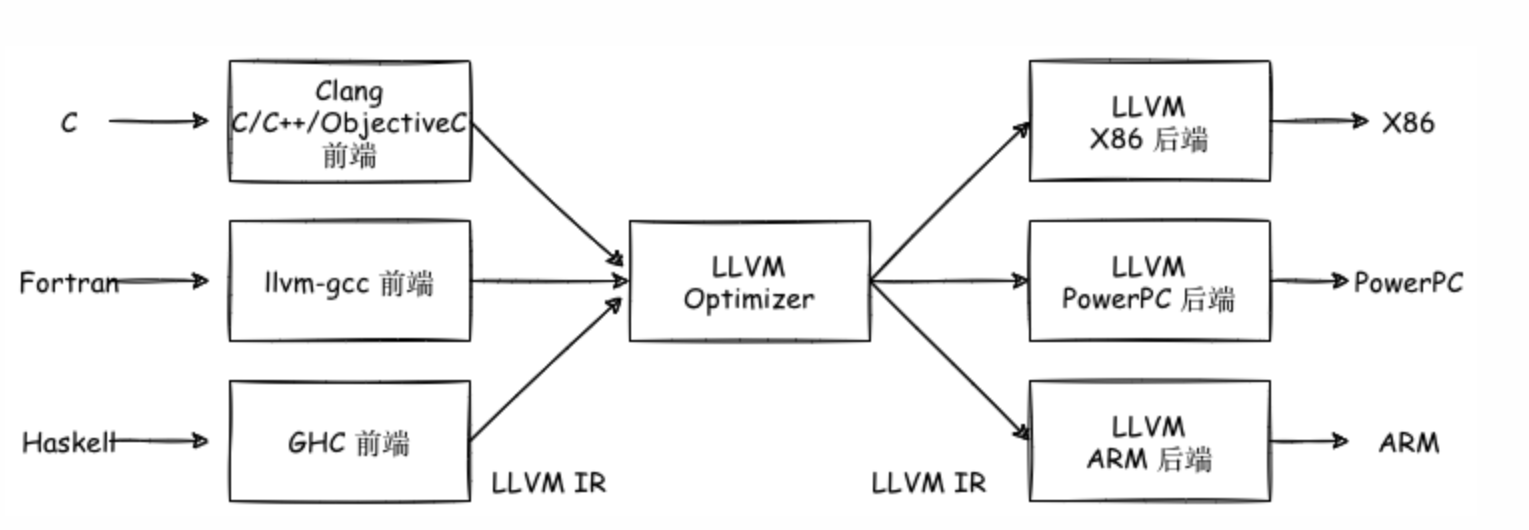
0x00 前言 为了解决使用AFL++进行Fuzzing的部分问题,个人决定对AFL的代码进行阅读,此为第二部分。 0x01 LLVM 1.1 起源 LLVM是底层虚拟机的英文缩写。 根据不同的场景,LLVM可能指示以下内容: LLVM项目/基础架构。此时,LLVM指代多个构建一个完整编译的项目,包括前端后端,优化器,汇编器,链接器,libc++。compiler-rt以及JIT引擎。 基于LLVM的编译器。此时LLVM指代部分或者完全采用LLVM基础架构构建的编译器。例如某个编译器可以采用LLVM作为前端或者后端…

0x00 事件背景 PyPI(Python Package Index)是Python官方的包索引和分发平台。它是一个公共的、全球性的存储库,用于存储、发布和安装Python包和模块。 PyPI允许开发者将他们编写的Python代码打包为可重用的模块或库,并将其发布到PyPI上供其他开发者使用。开发者可以通过使用pip工具(Python的包管理工具)从PyPI上安装所需的模块或库。PyPI提供了一个广泛的Python包,涵盖了各种用途和领域的功能。 0x01 事件过程 2023年4月17日ReversingLabs…
0x00 事件背景 CVE-2023-20871是Pwn2Own温哥华黑客大赛,由STAR Labs团队的安全人员展示的漏洞。其是基于堆栈的缓冲区溢出漏洞,存在于Vmware的虚拟机共享主机设备蓝牙的功能中。 CVE-2023-35829是Linux内核版本6.3.2之前的一个漏洞,其存在于rivers/staging/media/rkvdec/rkvdec.c 的 rkvdec_remove 函数中,是一个UAF(use-after-free,释放后重用)漏洞。 0x01 事件过程 2023年7月3日,GitHu…
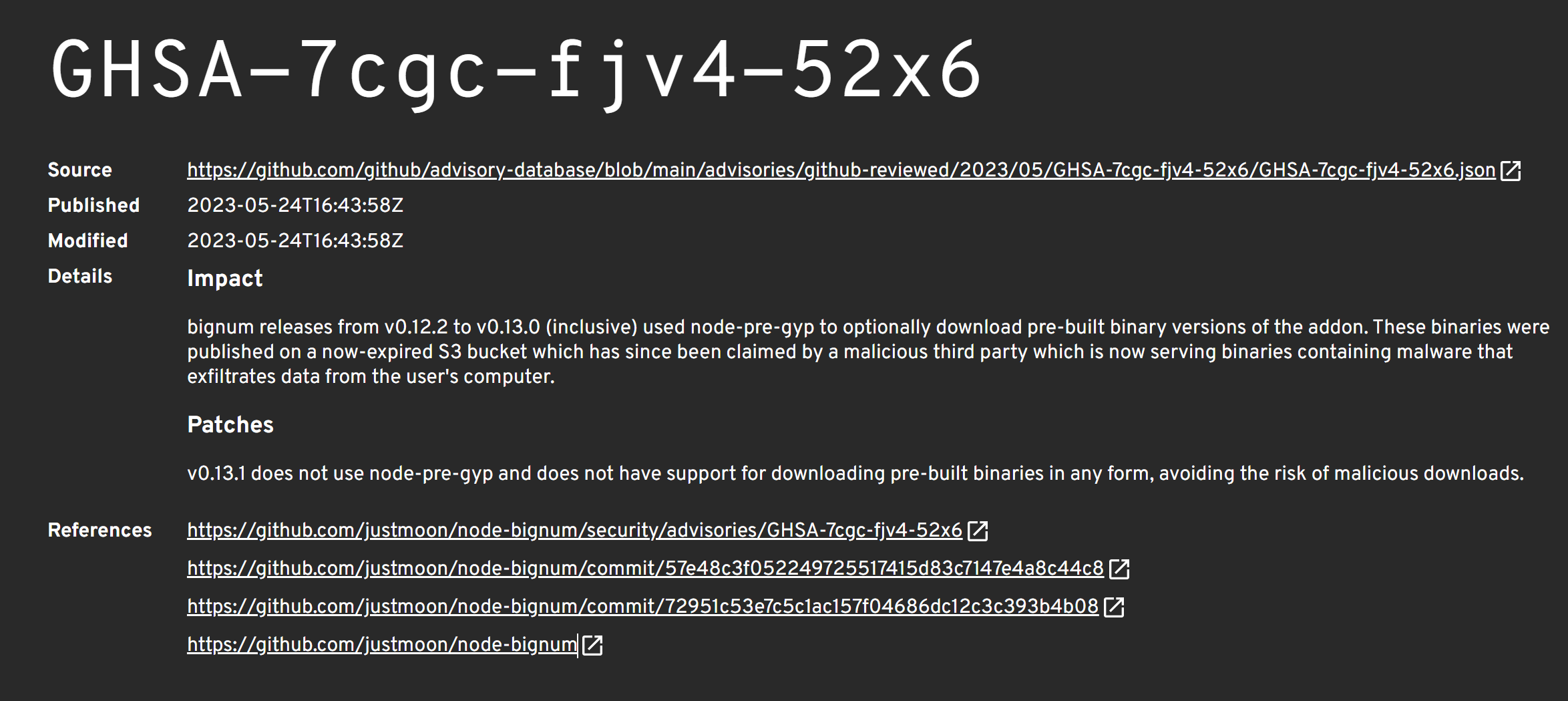
0x00 事件背景 NPM(Node Package Manager)是Node.js的软件包管理器,用于管理和分发JavaScript代码库。通过NPM,您可以方便地安装、更新和删除JavaScript库,以及管理项目的依赖关系。 node-pre-gyp是一个用于简化 Node.js 本机模块构建和发布的工具,它提供了统一的构建和安装流程,并自动处理不同平台和架构的差异。这样,开发人员可以更方便地创建和分发本机模块,同时提供更好的跨平台兼容性和易用性。 S3 Bucket是 AWS (Amazon Web Se…
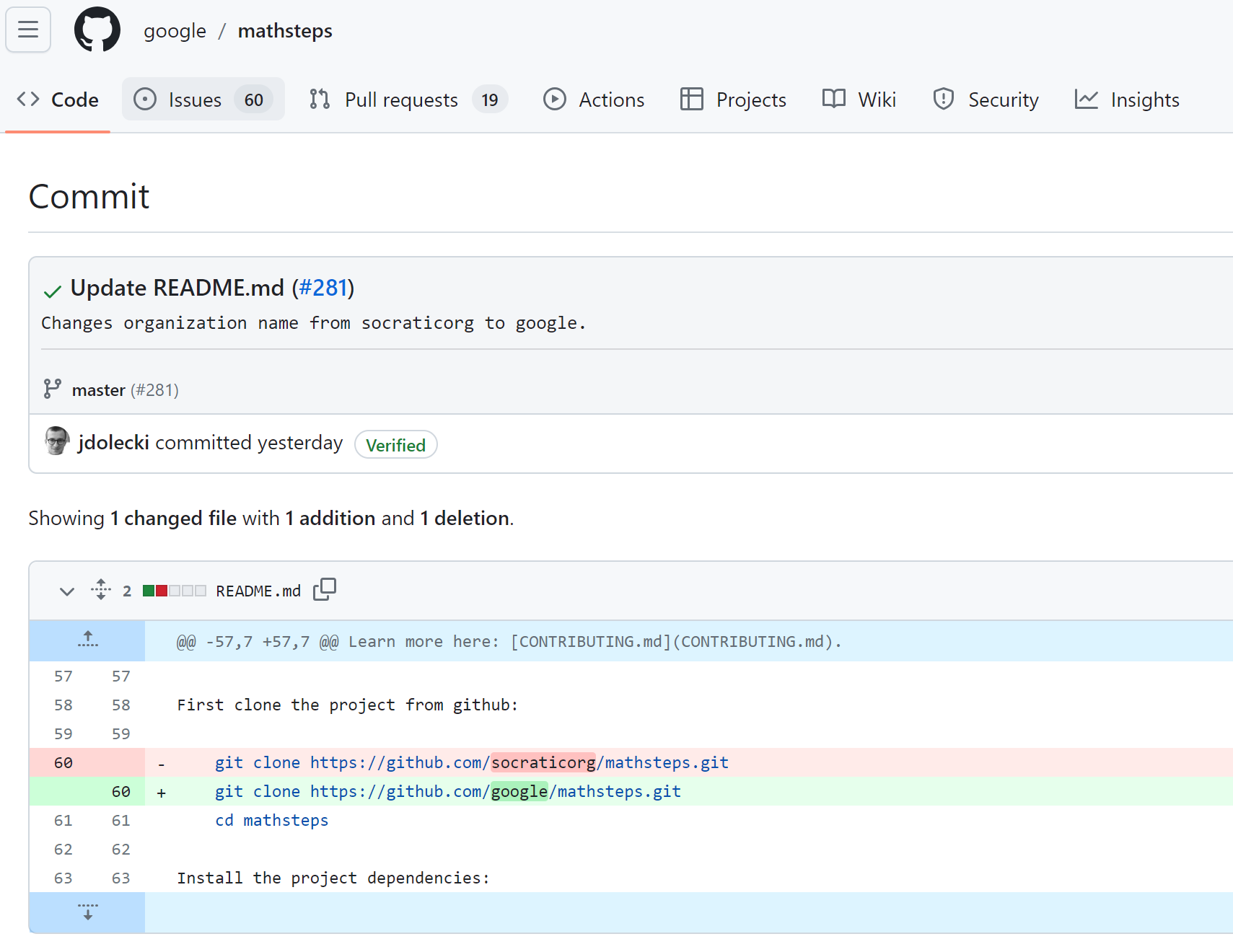
0x00 事件背景 GitHub是一个基于Web的代码托管平台和开发者社交网络。它提供了仓库(Repositories)用于存放代码,并提供了版本控制功能,使多人协作开发变得更加高效和便捷。GitHub允许开发者将自己的代码存储在云端仓库中,并进行版本管理。它使用分布式版本控制系统Git,使开发者可以轻松跟踪、管理和协作开发项目。 RepoJacking(仓库劫持)是指攻击者通过获取对原始仓库的控制权来替换或篡改代码库的行为。这种攻击通常发生在代码托管平台(如GitHub)上。 0x01 历史事件 2021年10月…
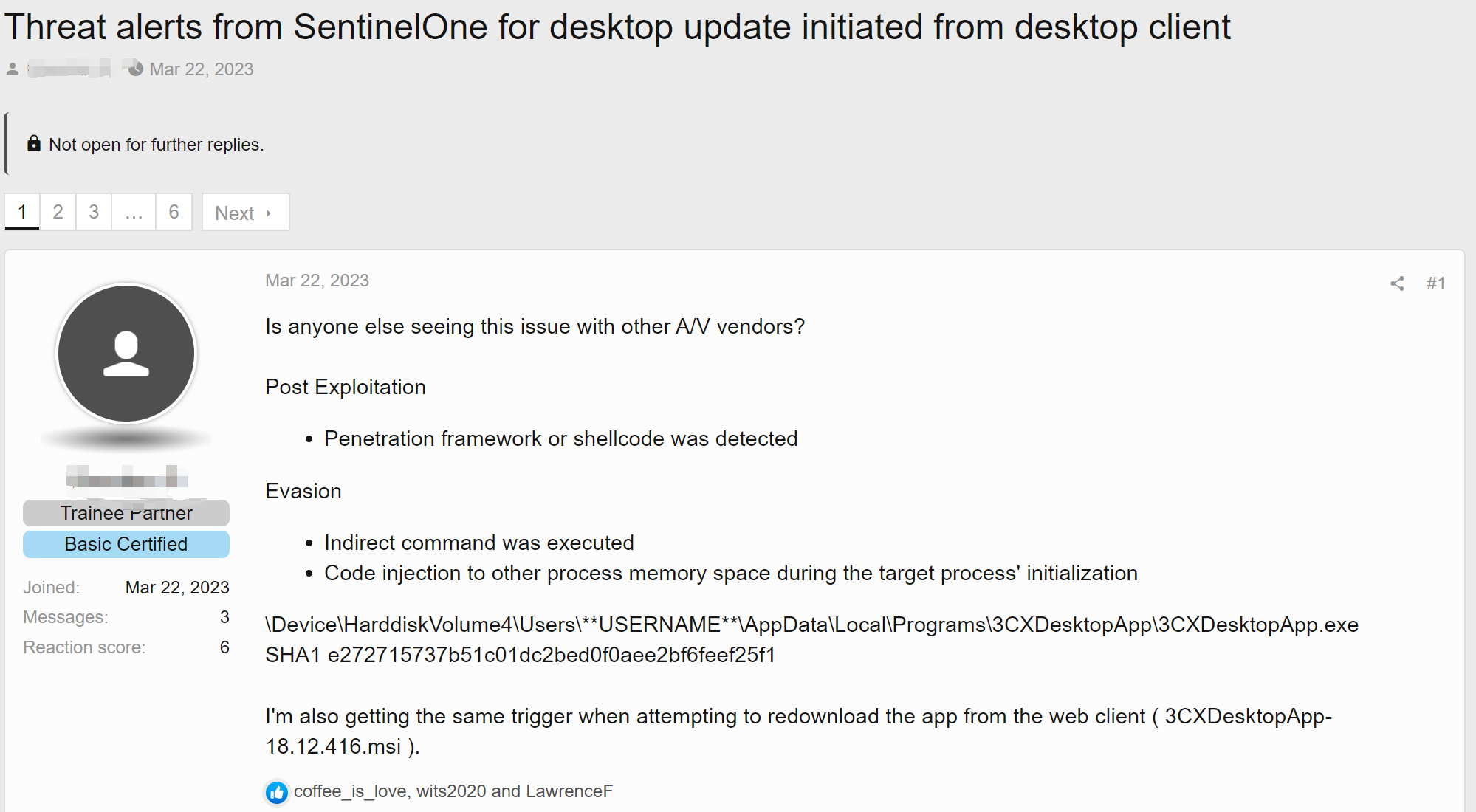
0x00 事件背景 3CX是一家软件公司,该公司提供一个基于软件的电话系统,用于企业或组织内部的通讯。3CX电话系统可以在Windows或Linux服务器上部署,并提供包括VoIP、PSTN和移动电话在内的多种通讯方式。此外,3CX还提供一系列的通讯软件,包括用于电脑、移动设备和浏览器的应用程序,可以让用户通过各种方式与其他人通讯。3CX声称其提供软件给600000多个客户,遍布全球190多个国家。 2023年3月29日,CrowdStrike发出告警,确定具有合法签名的二进制程序3CXDesktopApp具有恶意…